Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are
배우게 될 것
Internet of Things (IoT)는 전례없는 양과 다양한 데이터를 생성합니다. 그러나 데이터가 분석을 위해 클라우드로 이동하는 시점까지는 데이터를 처리 할 수 있는 기회가 사라질 수 있습니다. IT 및 운영 기술 전문가를 대상으로 이 백서는 IoT 데이터를 분석하고 작동하는 새로운 모델을 설명합니다. Edge 컴퓨팅 또는 Fog 컴퓨팅이라고 합니다 :
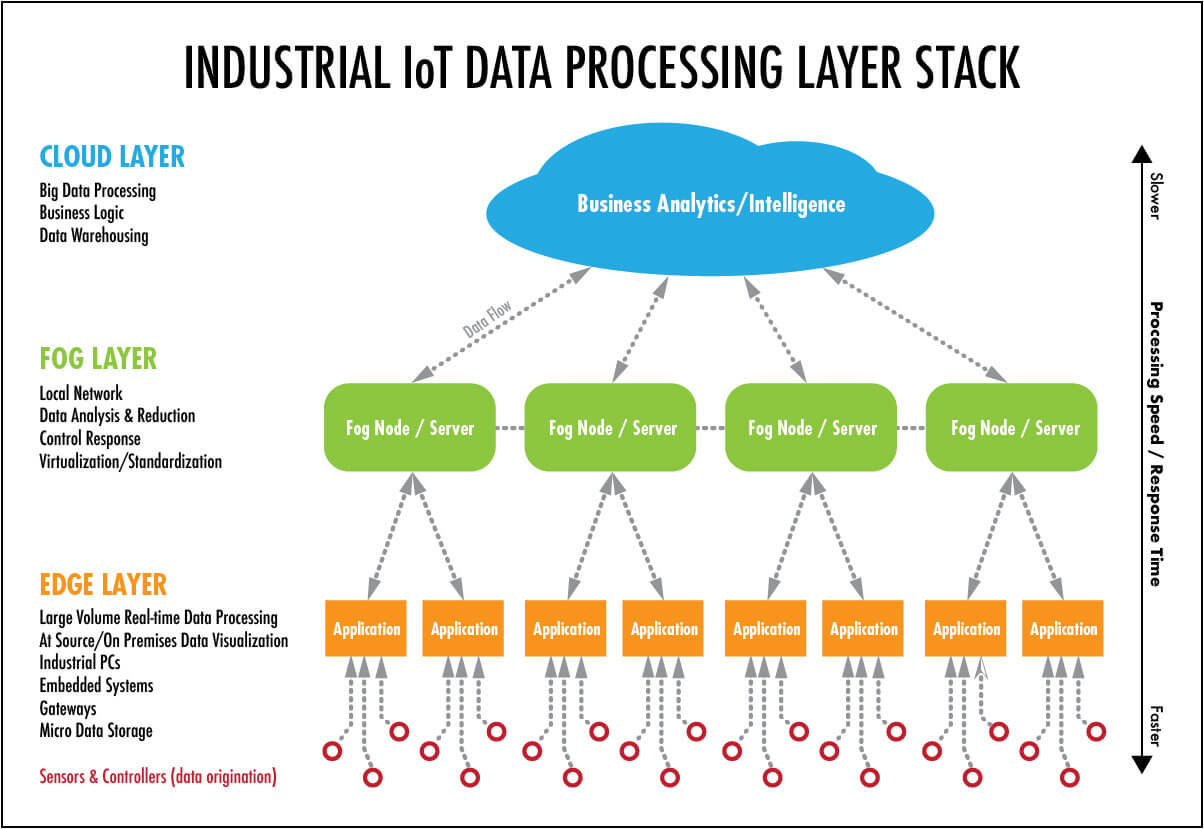
- 방대한 양의 IoT 데이터를 클라우드로 보내는 대신 네트워크 Edge에서 가장 시간에 민감한 데이터를 분석합니다.
- 정책에 따라 IoT 데이터에 대한 밀리 초 단위로 작동합니다.
- 과거 분석 및 장기 저장을 위해 선택한 데이터를 클라우드로 전송합니다.
IoT 가 비즈니스에 주는 의미
IoT는 사건에 대한 인식과 대응을 가속화 합니다. 제조, 석유 및 가스, 공공 설비, 운송, 광업 및 공공 부문과 같은 산업에서보다 빠른 응답 시간은 출력을 향상시키고 서비스 수준을 높이며 안전성을 높일 수 있습니다.
상상해보십시오: 공장 현장에서는 중요한 기계의 온도 센서가 임박한 고장과 관련된 판독 값을 전송합니다. 고비용의 시스템 종료를 피하기 위해 기술자가 파견되어 제시간에 장비를 수리합니다. 석유 및 가스 탐사의 경우, 송유관의 센서가 압력 변화를 등록합니다. 이에 따라 펌프는 자동으로 천천히 재난을 피합니다. 유틸리티 분야의 원격 현장 변전소에있는 견고한 카메라는 침입자를 탐지하고 경비원에게 경고합니다. 거의 즉각적인 분석은 다른 변전소에서 유사한 사건을 보여 주며 자동으로 경보를 최고 수준으로 끌어 올립니다.
새로운 종류의 thing 을 인터넷에 연결하는 것은 새로운 비즈니스 기회를 창출합니다. 예로는 유료 운전 차량 보험, 점등 서비스, Machine as a Service (MaaS) 등이 있습니다.
IoT 가 인프라에 미치는 영향
IoT를 이용하려면 새로운 종류의 인프라가 필요합니다. 오늘날의 클라우드 모델은 IoT가 생성하는 데이터의 양, 다양성 및 속도를 위해 설계되지 않았습니다. 이전에 연결되지 않은 수십억 개의 장치가 매일 2엑사 바이트 이상의 데이터를 생성하고 있습니다. 2020 년까지 약 500 억 개의 "thing" 이 인터넷에 연결됩니다. 분석을 위해 이러한 데이터를 클라우드로 이동하려면 막대한 양의 대역폭이 필요합니다.
오늘날의 클라우드 모델은 IoT가 생성하는 데이터의 양, 다양성 및 속도를 위해 설계되지 않았습니다.
수십억 가지의 새로운 thing 들은 또한 수많은 새로운 유형의 thing 들을 나타냅니다 (그림 1). 일부는 IP가 아닌 산업용 프로토콜을 사용하여 컨트롤러에 연결되는 기계입니다. 이 정보를 분석 또는 저장을 위해 클라우드로 보내기 전에 IP로 변환해야합니다.
그림1. 서로 다른 종류의 것들을 클라우드에 직접 연결하는 것은 비현실적입니다.
문제를 복잡하게하는 IoT 장치는 끊임없이 데이터를 생성하며 종종 분석이 매우 빨라야합니다. 예를 들어, 화학용 탱크의 온도가 허용 한계에 빠르게 도달 할 경우, 즉시 교정 조치를 취해야합니다. 분석을 위해 온도 판독 값이 Edge 에서 클라우드로 이동하는 데 시간이 걸릴 때, 손상된 배치를 피할 수 있는 기회가 손실 될 수 있습니다.
IoT 데이터의 볼륨, 다양성 및 속도를 처리하려면 새로운 컴퓨팅 모델이 필요합니다. 주요 요구 사항은 다음과 같습니다.
- 대기 시간 최소화: 제조 라인 종료를 막거나 전기 서비스를 복원하려고 할 때 밀리 세컨드가 중요합니다. 데이터를 수집 한 장치 가까이에서 데이터를 분석하면 재난을 피할 수 있고 계단식 시스템 오류를 피할 수 있습니다.
데이터를 수집 한 장치 가까이에서 데이터를 분석하면 재난을 피할 수 있고 계단식 시스템 오류를 피할 수 있습니다.
-
네트워크 대역폭 절약(Conserve): 해외 석유 회사는 매주 500GB의 데이터를 생성합니다. 상용 제트기는 매 30 분마다 10TB를 생성합니다. 수천 또는 수십만 대의 Edge 장치에서 클라우드로 방대한 양의 데이터를 전송하는 것은 현실적이지 않습니다. 또한 많은 중요한 분석에는 클라우드 규모의 처리 및 저장이 필요하지 않기 때문에 필요하지 않습니다.
-
주소 보안 문제: IoT 데이터는 전송 중 및 휴식 중에 모두 보호해야합니다. 이를 위해서는 전, 후 및 후 전체 공격 연속체에 걸친 모니터링 및 자동 대응이 필요합니다.
-
안정적 운영(reliably): IoT 데이터는 시민 안전 및 중요한 인프라 스트럭처에 영향을 미치는 결정에 점점 더 많이 사용됩니다. 인프라 및 데이터의 무결성 및 가용성은 문제가 될 수 없습니다.
-
환경 조건이 다른 넓은 지역의 데이터 수집 및 보안: IoT 장치는 수백 평방 마일 이상 분산 될 수 있습니다. 도로, 철도, 공공 시설 변전소 및 차량과 같은 열악한 환경에 배치 된 장치는 견고해야합니다. 제어 된 실내 환경의 장치는 그렇지 않습니다.
-
처리를위한 최상의 장소로 데이터 이동: 결정이 얼마나 신속하게 필요한지에 따라 부분적으로 좌우됩니다. 매우 시간에 민감한 결정은 데이터를 생산하고 행동하는 것에 더 가깝게해야합니다. 반면, 과거 데이터에 대한 대용량 데이터 분석에는 클라우드의 컴퓨팅 및 스토리지 리소스가 필요합니다.
전통적인 클라우드 컴퓨팅 아키텍처는 이러한 모든 요구 사항을 충족하지 못합니다. 네트워크 Edge 에서 데이터 센터로 모든 데이터를 이동시켜 처리하기 때문에 대기 시간이 늘어납니다. 수천 개의 장치로부터의 트래픽은 곧 대역폭 용량을 능가합니다. 산업 규정 및 개인 정보 보호 문제는 특정 유형의 데이터를 오프 사이트에 저장하는 것을 금지합니다. 또한 클라우드 서버는 IoT 장치에서 사용되는 수많은 프로토콜이 아닌 IP와 만 통신합니다. 대부분의 IoT 데이터를 분석하기에 이상적인 곳은 해당 데이터를 생성하고 작동하는 장치입니다. 우리는 Fog 컴퓨팅이라고 부릅니다.
Fog Computing 101
그것은 무엇인가? Fog 는 IoT 데이터를 생성하고 작동하는 것과 더 가깝도록 클라우드를 확장합니다 (그림 2). Fog 노드 (fog node)라고 불리는 이러한 장치는 공장 바닥, 전원 극 위에, 철도 트랙, 차량 또는 유정에서 네트워크 연결을 통해 어디에서나 설치할 수 있습니다. 컴퓨팅, 스토리지 및 네트워크 연결이 있는 모든 장치는 Fog 노드 일 수 있습니다. 예로는 산업용 컨트롤러, 스위치, 라우터, 임베디드 서버 및 비디오 감시 카메라가 있습니다.
IDC는 물리적으로 thing 의 인터넷에 가까운 장치에서 분석되는 데이터의 양이 40%에 달한다고 추정합니다. 수집 된 곳 가까이에서 IoT 데이터를 분석하면 지연 시간이 최소화됩니다. 핵심 네트워크에서 기가 바이트의 네트워크 트래픽을 분산시켜 네트워크 내에서 중요한 데이터를 유지합니다.
IoT 데이터를 수집 한 곳 가까이에서 분석하면 대기 시간을 최소화 할 수 있습니다. 코어 네트워크에서 기가 바이트의 네트워크 트래픽을 분산시킵니다. 또한 민감한 데이터를 네트워크 내부에 보관합니다.

그림2. Fog는 클라우드 클로저를 데이터를 생성하는 장치로 확장
Examples of Fog Applications Fog 적용은 사물의 인터넷 자체만큼 다양합니다. 공통점은 네트워크로 연결된 사물의 실시간 데이터를 모니터링 하거나 분석 한 다음 조치를 취하는 것입니다. 이 작업에는 M2M (Machine-to-Machine) 통신 또는 HMI (Human-Machine Interaction)가 포함될 수 있습니다. 예를 들어, 문 잠그기, 장비 설정 변경, 열차에서 브레이크 적용, 비디오 카메라 확대 / 축소, 압력 판독에 대한 밸브 열림, 막 대형 차트 작성 또는 기술자에게 경고를 보내 예방 수리를 할 수 있습니다. 가능성은 무제한입니다. Fog 응용 분야는 제조, 석유 및 가스, 유틸리티, 운송, 광업 및 공공 부문에서 급속도로 확산되고 있습니다.
Fog 컴퓨팅을 고려해야하는 경우
- 차량, 선박, 공장 바닥, 도로, 철도 등 극한의 데이터 수집.
- 넓은 지리적 영역에서 수천만 개의 thing이 데이터를 생성하고 있습니다.
- 1 초 이내에 데이터를 분석하고 작동해야합니다.
How Does Fog Work? 개발자는 네트워크 Edge에서 Fog 노드에 대한 IoT 애플리케이션을 포트하거나 씁니다. 네트워크 Edge에 가장 가까운 Fog 노드는 IoT 장치의 데이터를 수집합니다. 그리고 Fog IoT 애플리케이션은 표 1에 나와있는 것처럼 다양한 유형의 데이터 분석을 위한 최적의 장소로 전달합니다.
- 가장 시간에 민감한 데이터는 데이터를 생성하는 것에 가장 가까운 Fog 노드에서 분석됩니다. 예를 들어, Cisco Smart Grid 분배 네트워크에서 가장 시간에 민감한 요구 사항은 보호 및 제어 루프가 올바르게 작동하는지 확인하는 것입니다. 따라서 그리드 센서에 가장 가까운 Fog 노드는 문제의 징후를 찾은 다음 액추에이터에 제어 명령을 전송하여 문제를 방지 할 수 있습니다.
- 조치를 위해 초 또는 분을 대기 할 수있는 데이터는 분석 및 조치를 위해 집계 노드로 전달됩니다. 스마트 그리드 예에서, 각 변전소는 각 다운 스트림 피더와 측면의 작동 상태를보고하는 자체 집합 노드를 가질 수있다.
- 시간이 덜 중요한 데이터는 과거 분석, 큰 데이터 분석 및 장기 저장을 위해 클라우드로 전송됩니다 (사이드 바 참조). 예를 들어, 수천 또는 수십만 개의 Fog 노드가 과거의 분석 및 저장을 위해 그리드 데이터의 주기적 요약을 클라우드에 보낼 수 있습니다.
표1. 클라우드를 네트워크 Edge로 확장시키는 Fog 노드
| Fog Nodes Closest to IoT Devices | Fog Aggregation Nodes | Cloud | |
|---|---|---|---|
| Response Time | 밀리 세컨드 | 초에서 분 | 분, 일, 주 |
| Application examples | M2M 통신 Haptics, 원격 진료 및 교육 포함 | 시각화, 간단한 분석 | 빅 데이터 분석, 그래픽 대시 보드 |
| How long IoT data is stored | 일시적 | 짧은 기간:몇 시간, 며칠 또는 몇 주 | 몇 달 또는 몇 년 |
| Geographic coverage | 매우 로컬: 예를 들어, 한 도시 블록 | 넓은 | 글로벌 |
Fog 와 클라우드에서 일어나는 일
Fog 노드:
- IoT 장치에서 실시간으로 프로토콜을 사용하여 피드를 수신합니다.
- 밀리 초 응답 시간으로 실시간 제어 및 분석을 위해 IoT 가능 애플리케이션 실행
- 일시적 저장 장치 제공, 보통 1-2 시간
- 정기적인 데이터 요약을 클라우드에 보냅니다.
클라우드 플랫폼 :
- 많은 Fog 노드에서 데이터 요약을 수신하고 집계합니다.
- 비즈니스 통찰력을 얻기 위해 다른 소스의 IoT 데이터 및 데이터에 대한 분석 수행
- 이러한 통찰력을 기반으로 Fog 노드에 새로운 애플리케이션 규칙을 보낼 수 있습니다.
Fog 컴퓨팅의 이점
클라우드를 데이터에 생성하고 작동하는 것에 더 가깝게 확장하면 다음과 같은 이점을 얻을 수 있습니다.
- 뛰어난 비즈니스 민첩성: 올바른 도구를 사용하여 개발자는 Fog 어플리케이션을 신속하게 개발하고 필요할 때 배포 할 수 있습니다. 기계 제조업체는 고객에게 MaaS를 제공 할 수 있습니다. Fog 어플리케이션은 각 고객이 필요로하는 방식으로 작동하도록 기계를 프로그래밍합니다.
- 향상된 보안성: IT 환경의 다른 부분에서 사용하는 것과 동일한 정책, 제어 및 절차를 사용하여 Fog 노드를 보호하십시오. 동일한 물리적 보안 및 사이버 보안 솔루션을 사용하십시오.
- 개인 정보 제어 기능이 추가 된 더 깊은 통찰력: 중요한 데이터를 분석을 위해 클라우드로 보내는 대신 로컬에서 분석하십시오. IT 팀은 데이터를 수집, 분석 및 저장하는 장치를 모니터링하고 제어 할 수 있습니다.
- 운영비 절감: 선택한 데이터를 분석을 위해 클라우드로 전송하는 대신 로컬로 처리하여 네트워크 대역폭을 보존합니다.
결론
Fog 컴퓨팅은 클라우드에 일의 인터넷에서 매일 생성되는 2 엑사 바이트의 데이터를 처리 할 수있는 동반자를 제공합니다. 데이터가 생성되고 필요한 곳 가까이에서 데이터를 처리하면 데이터 양, 다양성 및 속도가 폭발하는 문제를 해결할 수 있습니다.
Fog 컴퓨팅은 분석을 위해 클라우드로의 왕복을 제거함으로써 이벤트에 대한 인식과 대응을 가속화합니다. 코어 네트워크에서 기가 바이트의 네트워크 트래픽을 처리하여 값 비싼 대역폭을 추가 할 필요가 없습니다. 또한 민감한 IoT 데이터를 회사 벽 내부에서 분석하여 보호합니다. 궁극적으로 Fog 컴퓨팅을 채택한 조직은보다 빠르고 정확한 통찰력을 확보하여 비즈니스 민첩성 향상, 서비스 수준 향상 및 안전성 향상을 이끌어냅니다.
'Data Centric Network' 카테고리의 다른 글
| whitepaper-fog-vs-edge_nebbiolo-technologies (0) | 2018.08.29 |
|---|---|
| Docker로 NFD 사용 (0) | 2018.06.20 |